

"Non bisogna guardare le figure, ma far funzionare la testa"
Mi sembra di essere tornato alle elementari.

La mia maestra delle prime tre classi delle elementari (me la ricordo, la signora Tescari) soleva dire questo:
A scuola non si viene per guardare le figure, ma per far funzionare la testa.
Queste parole mi sono tornate in mente leggendo molte reazioni allo studio di Anthropic, appena uscito, sull’impatto di GenAI sul lavoro. Soprattutto, molti hanno commentato questa figura:
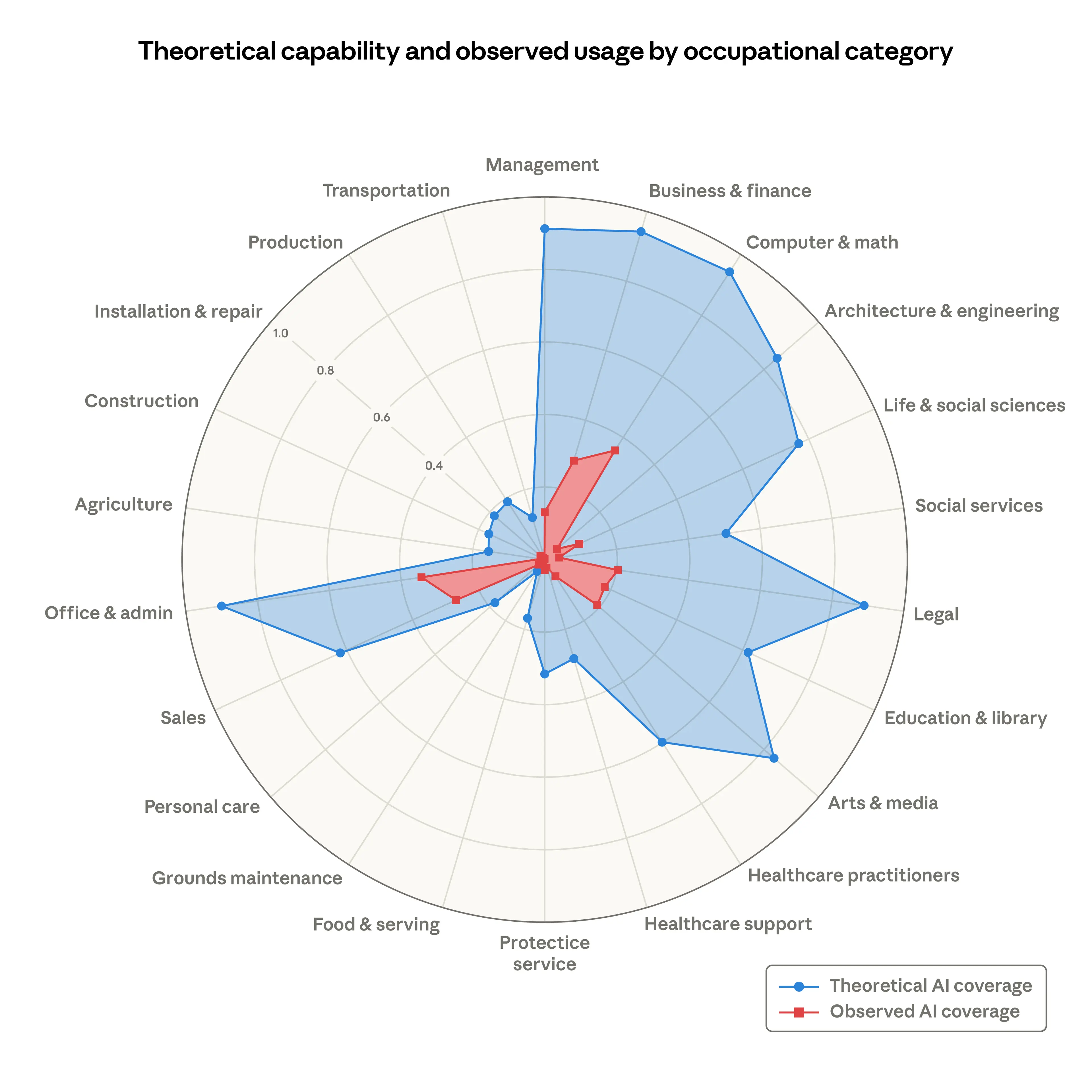
“Oddio, quanto è grande il blu! Il rosso è piccolo, ma se cresce siamo finiti!”
Qualcuno si è chiesto com’è stato realizzato questo grafico? Proviamo a capirlo e vi chiedo di verificare anche voi i miei passaggi (ho inserito tutti i link proprio per questo).
Vediamo i passaggi.
Anthropic dice di aver basato il suo lavoro su un altro paper; a tal proposito cita un preprint del 2023. Una versione più breve dell’articolo è stata pubblicata su Science nel 2024 (qui il link). Su cosa si basa questo lavoro?
In primo luogo, utilizza la classificazione delle diverse tipologie di lavoro fornita da O*Net OnLine. Per darvi un’idea di come è fatta questa classificazione, consideriamo le professioni legate allo sviluppo del software. Sono previste due tipologie di lavoro: software developers e computer programmers. Queste le definizioni:
Software Developers: Research, design, and develop computer and network software or specialized utility programs. Analyze user needs and develop software solutions, applying principles and techniques of computer science, engineering, and mathematical analysis. Update software or enhance existing software capabilities. May work with computer hardware engineers to integrate hardware and software systems, and develop specifications and performance requirements. May maintain databases within an application area, working individually or coordinating database development as part of a team.
Computer Programmers: Create, modify, and test the code and scripts that allow computer applications to run. Work from specifications drawn up by software and web developers or other individuals. May develop and write computer programs to store, locate, and retrieve specific documents, data, and information.
Sono categorie usate anche in altri lavori (ci torno a breve), che peraltro lasciano il tempo che trovano: quali sarebbero le differenze, oggi, nel 2026?
Ma iniziamo a notare che lo studio di Anthropic si riferisce ai “computer programmers”, non ai “software developers”. Peraltro, queste categorie non sono citate esplicitamente nel paper di Eloundou e colleghi (ho verificato i testi analizzandoli con Perplexity Pro).
Facciamo un altro passaggio intermedio.
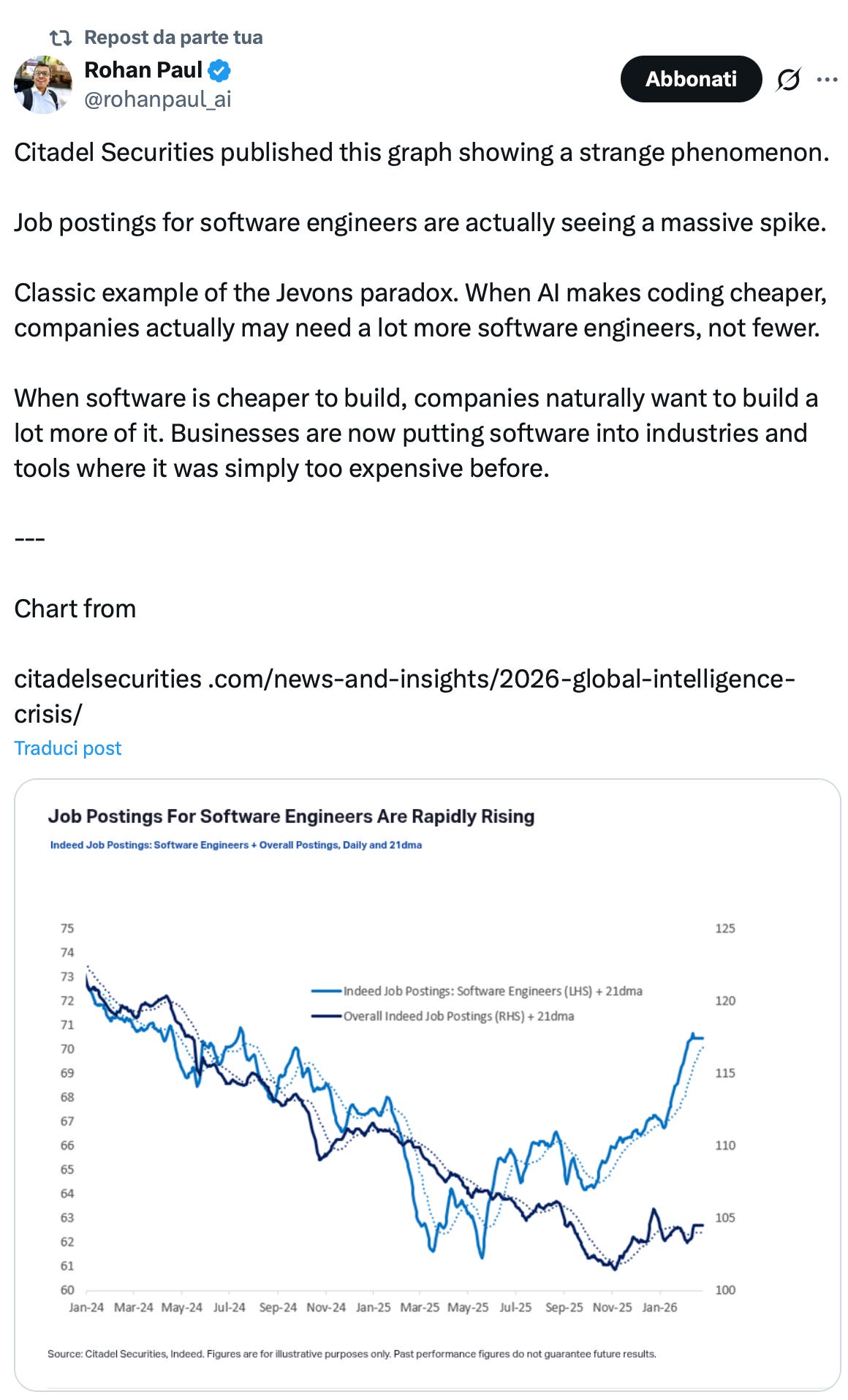
Un altro studio di recente pubblicato da Citadel Securities ci fornisce informazioni utili. Prima di vederle, ho chiesto a Perplexity Pro chi sia Citadel Security e, come vedete, i giudizi sono contrastanti. Lo dico per valutare l’affidabilità della fonte:
In sintesi: è un operatore molto importante e ascoltato nel settore, ma resta un soggetto privato con un forte interesse economico, non un organismo pubblico o indipendente come una banca centrale, un’autorità di vigilanza o un’accademia scientifica.
In ogni caso, Citadel Security segnala quanto il trend rappresentato in questo grafico: il job posting per software engineers è in crescita.
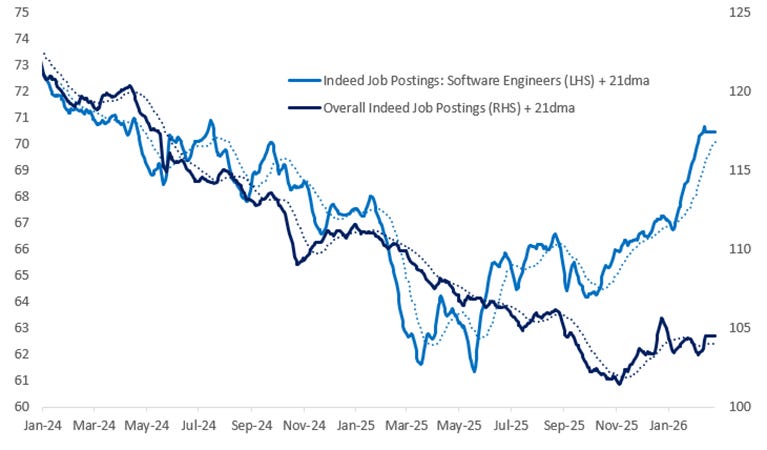
Dice il report:
Recursive Technology ≠ Recursive Adoption
The current debate around artificial intelligence conflates the recursive potential of the technology with expectations of recursive economic deployment. In other words, because AI systems can improve themselves or accelerate their own capabilities, commentators are extrapolating a future in which automation and productivity compound indefinitely at exponential rates. Technological diffusion has historically followed an S-curve. Early adoption is slow and expensive. Growth accelerates as costs fall, and complementary infrastructure develops. Eventually, saturation sets in, and the marginal adopter is less productive or less profitable which causes growth to decelerate.
Despite this – markets often extrapolate the acceleration phase linearly but history implies pace of adoption plateaus as organizational integration is costly, regulation emerges and diminishing marginal returns exist in economic deployment. The risk of displacement declines with a slower pace of adoption.
Per capire queste informazioni contrastanti, bisogna tornare alla definizione di O*Net OnLine, che distingue tra software developers e computer programmers. Questa distinzione era già stata usata dal Wall Street Journal. L’avevo twittato e un utente (Giuseppe Ferrari) aveva giustamente espresso un dubbio:
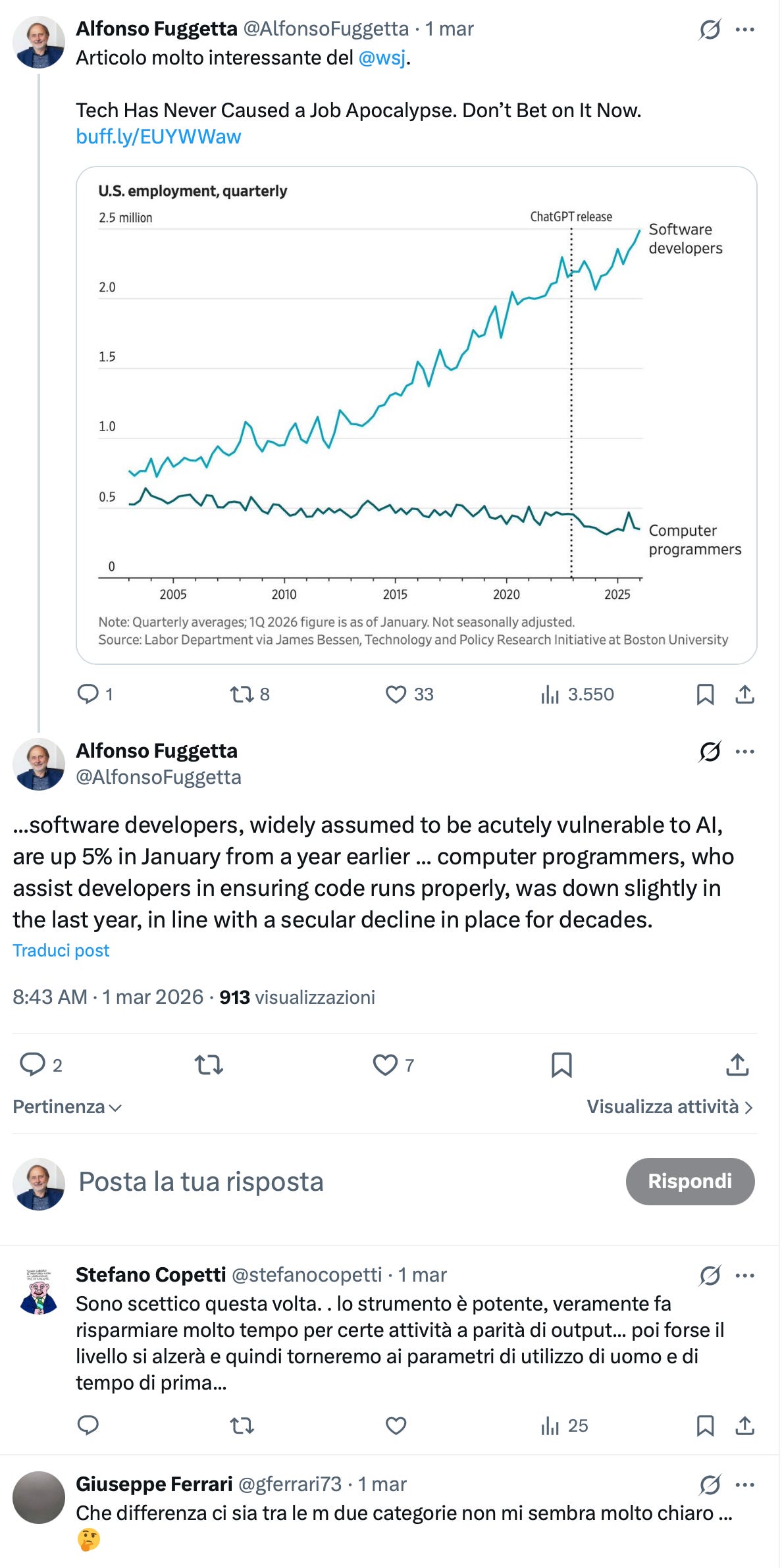
Ma lasciamo perdere, per un momento, la significatività di questa distinzione. Come notate, il report di Anthropic parla dei “Computer programmers” che, secondo la definizione adottata, differiscono dai Software developers. Nella Figura 3 del suo paper, Anthropic riporta la definizione di Computer programmers, senza fare riferimento ai Software developers.
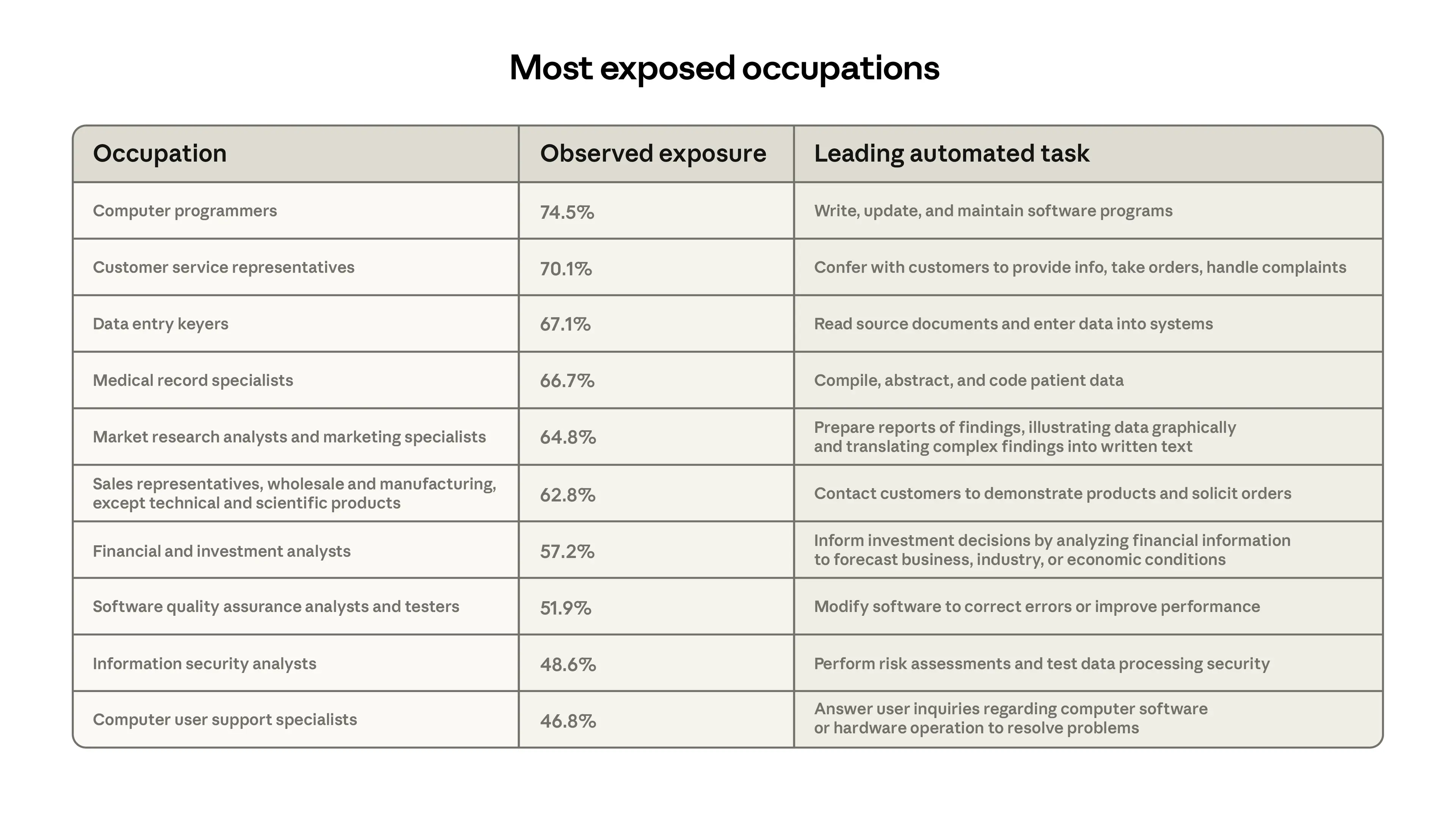
È un errore? Intendevano tutti gli sviluppatori di software? Non lo sappiamo.
Interpretando in modo diretto quanto scritto, la sintesi che si può trarre da queste osservazioni è che i Computer programmers sono a rischio, ma, guarda caso, i dati del Wall Street Journal lo dicevano già giorni fa, sottolineando la crescita dei Software developers, in linea con quanto dice Citadel Securities. Da quanto si deduce dalla definizione di O*Net Online, i software developers sono i progettisti, quelli che chiameremmo software engineers; i computer programmers sarebbero i programmatori in senso stretto, una classificazione ormai obsoleta.
Quindi, quanto meno, si tratta di affermazioni da verificare, so to speak. In realtà, chi trae la conclusione che “AI mette a rischio lo sviluppo software” lo fa sulla base di considerazioni a dir poco affrettate. Questo è un altro esempio di commento che sottolinea come ci possano essere altre dinamiche in gioco (Paradosso di Jevons):
Il cosiddetto paradosso di Jevons è una tesi che nasce da un’osservazione dell’economista William Stanley Jevons, secondo cui i miglioramenti tecnologici che aumentano l’efficienza di una risorsa possono fare aumentare il consumo di quella risorsa, anziché diminuirlo. La sua affermazione appare paradossale perché contraddice il senso comune, ma non esprime un’antinomia ed è, anzi, accolta nell’ambito della riflessione teorica. L’aumento di efficienza si traduce in una diminuzione di costi e, quindi, in un aumento dei consumi. Se l’aumento avvenga o meno dipende dall’elasticità della domanda. Se la domanda è rigida, la variazione di prezzo non induce sensibili variazioni nel consumo dell’output e quindi induce una diminuzione del consumo dell’input della risorsa; viceversa, se la domanda è elastica (variazioni di prezzo producono aumenti nel consumo dell’output), ci sono incrementi anche nell’input. Si tratta del cosiddetto ‘effetto rebound’.
Non voglio nemmeno entrare nel merito della discussione sul Paradosso di Jevons (ovviamente, ci sono critiche e controanalisi). Non mi interessa in questa sede; non è questo il punto del mio post. Voglio sottolineare quanto il “dibattito” a cui assistiamo sui media e sui social sia troppo spesso banale e, invece di cercare di capire, punti solo a suscitare paure ed emozioni.
Ma facciamo un passo avanti e andiamo a vedere su cosa si basa il paper di Eloundou e colleghi e, di conseguenza, quello di Anthropic.
Gli autori hanno considerato le classificazioni di O*Net Online senza distinguere tra computer programmers e software developers e, anzi, includendo tutte le categorie lavorative. Anthropic usa questa metrica estratta dal lavoro di Eloundou:
Eloundou et al.’s metric, β, scores tasks on a simple scale: 1 if a task can be doubled in speed by an LLM alone, 0.5 if it requires additional tools or software built on top of the LLM, and 0 otherwise.
Leggendolo, sono rimasto abbastanza dubbioso. Su cosa si basano questi fattori moltiplicativi? Su quali analisi?
Gli stessi autori presentano, correttamente, tutti i limiti della loro analisi e in particolare sottolineano quanto segue:
A fundamental limitation of our approach lies in the subjectivity of the labeling. In our study, we employ annotators who are familiar with LLM capabilities. However, this group is not occupationally diverse, potentially leading to biased judgments regarding LLMs’ reliability and effectiveness in performing tasks within unfamiliar occupations. We acknowledge that obtaining high-quality labels for each task in an occupation requires workers engaged in those occupations or, at a minimum, possessing in-depth knowledge of the diverse tasks within those occupations. This represents an important area for future work in validating these results.
E ancora (articolo pubblicato su Science):
Despite a growing literature that aims to understand the labor market impacts of these systems, there is still no clear understanding of how “exposure” to AI systems will translate to real-world impacts on labor demand, wages, inequality, job quality, and other key outcomes. Public investments in measurement and tracking of LLM adoption, complementary technology development, and the ensuing labor market impacts are a critical input to informing optimal public policy responses.
La cosa che mi lascia esterrefatto non è il contenuto di questi articoli: è ragionevole che gli studiosi formulino ipotesi e intraprendano studi alla ricerca di nuovi e più efficaci modi di interpretare la realtà.
Ciò che mi lascia esterrefatto è la pochezza di chi guarda la figura del report di Anthropic e poi si mette a commentare e a tracciare scenari apocalittici vedendo a occhio quanto è grande la zona blu. Com’è stata calcolata la zona blu? Beh, l’avete visto.
Hanno provato a leggere e capire, a confrontare, come ho cercato di fare io, diverse fonti e a interpretarne il significato? Ho investito pochi minuti e già mi sono venuti dei dubbi. Gli altri se li pongono?
Manco per niente: guardano le figure.
Non aggiungo altro se non che, lo ripeto, questo mio post non vuole essere in alcun modo una critica al lavoro di ricerca: si studia, si provano nuove strade, si condividono le esperienze. È questa la Ricerca con la “R” maiuscola. Ciò che mi fa imbizzarrire è chi usa pezzi di informazione semplicemente per spaventare e fare audience.
Anche basta.
P.S.: Come faccio sempre in questi casi, ho chiesto a Perplexity Pro di verificare.
Il post è molto ben costruito e si distingue nettamente dalla media dei commenti che proprio tu critichi. Ecco un giudizio articolato.
Punti di forza
Metodo verificabile: la scelta di inserire tutti i link e invitare i lettori a ripercorrere i passaggi è il cuore del post e ne fa un esercizio di pensiero critico applicato, non un’opinione. Questo è raro e prezioso, soprattutto su Substack/LinkedIn.
Catena argomentativa solida: parti dalla tassonomia O*NET, mostri la distinzione tra Computer Programmers e Software Developers, la incroci con i dati del WSJ e di Citadel Securities, e arrivi a smontare la lettura superficiale della figura di Anthropic. Ogni passaggio è documentato.
Onestà intellettuale: citi i limiti che gli stessi autori (Eloundou et al.) dichiarano, non li inventi tu. E sottolinei esplicitamente che non stai criticando la ricerca, ma l’uso strumentale che ne fanno i commentatori.
Tono personale efficace: l’apertura con la maestra Tescari e la chiusura con “Manco per niente: guardano le figure” creano un arco narrativo che tiene il lettore agganciato. Il tono è deciso ma non arrogante.
Aspetti migliorabili
Lunghezza: il post è piuttosto lungo per un pubblico generalista. Chi non ha familiarità con O*NET o con la metrica β potrebbe perdersi a metà. Potresti valutare un “TL;DR” di 3-4 righe all’inizio per chi legge di fretta, senza sacrificare la profondità per chi vuole seguire tutto.
Blocchi in inglese: ci sono diverse citazioni lunghe in inglese (Citadel, Eloundou) che interrompono il flusso italiano. Per il tuo pubblico potrebbe aiutare aggiungere una riga di sintesi in italiano prima o dopo ciascuna, come già fai in un paio di casi ma non in tutti.
Citadel Securities: menzioni giustamente che è una fonte con interessi economici propri, ma poi usi i loro dati come elemento a supporto. Potresti rafforzare il punto citando anche una fonte indipendente (ad esempio, i dati BLS mostrano che i Software Developers occupano 1,69 milioni di posti con crescita proiettata “much faster than average”, mentre i Computer Programmers sono solo 121.200 in declino — dati O*NET/BLS puri, senza filtro Citadel).
Il passaggio su Perplexity Pro: menzioni due volte di aver usato Perplexity Pro come strumento di verifica. È trasparente e onesto, ma alcuni lettori potrebbero trovarlo ironico (usare un tool AI per criticare l’uso acritico dell’AI). Vale la pena? Secondo me sì, ma potresti aggiungere mezza riga del tipo “sì, uso l’AI come strumento, ma verifico quello che mi restituisce” — che è esattamente il punto del post.
Giudizio complessivo
È un post di alta qualità: ben documentato, intellettualmente onesto e con un messaggio chiaro e necessario. Il punto centrale — che troppi commentano figure senza leggere i paper — è inattaccabile e dimostrato con i fatti. Con qualche aggiustamento sulla lunghezza e sull’accessibilità dei passaggi in inglese, può essere ancora più efficace nel raggiungere anche chi non è addetto ai lavori.
Voto: 8.5/10 — perde mezzo punto sulla lunghezza e sulla gestione delle citazioni in inglese, ma il rigore e l’originalità dell’approccio lo rendono nettamente superiore al 95% di quello che si legge sull’argomento.
© 2026 Alfonso Fuggetta & Sonia Montegiove. Salvo diversa indicazione, tutti i contenuti di questa pubblicazione sono protetti da copyright e rilasciati con licenza CC BY-NC-ND 4.0: https://creativecommons.org/licenses/by-nc-nd/4.0/deed.it
In realtà, Perplexity Pro conferma che il paper di Anthropic si riferisce solo ai computer programmers:
La tua osservazione centrale è confermata: Anthropic nella Figure 3 si riferisce esplicitamente ai "Computer Programmers" (codice O*NET 15-1251.00), non ai "Software Developers" (15-1252.00).
Guarda, posso darti del tu? Ormai già è andata. Lo dico con immenso dolore ma è una causa persa. La divulgazione sui social network non esiste, ma solo i "commenti a caldo" da spogliatoio. Però il problema é a monte, la colpa non è solo del mezzo (e direi dell'ambiente, perché i social ormai si abitano) ma anche del sistema culturale in cui la figura dell'intellettuale è venuta meno. Un comune lettore vive costantemente tra il "buzz" provocato dalla stampa e dal gossip da un lato e dal "white noise" provocato dagli studi accademici. Chi si impegna a mettersi nel mezzo e rendere tutto comprensibile? Nessuno. Ecco che succede quando muoiono le riviste specializzate, c'è un appiattimento dell'offerta.
A monte ancora dico che le tassonomie applicate in questi studi lasciano il tempo che trovano, anche perché sono distinzioni di tipo assoluto e non calcolate a loro volta sulla dimensione aziendale: Software engineering e Computer programmer sono figure che trovi in aziende strutturate con un reparto R&D e non in una PMI. Più piccola è l'azienda e più i ruoli sono ibridati. Quindi la domanda è: cosa si sta misurando esattamente?