

L'harness, ovvero il ritorno dell'ingegneria del software
Ho letto un pezzo sull'architettura degli agenti AI e ho riconosciuto trent'anni di storia di questa disciplina.

Questo post fa parte della serie dedicata al rapporto tra l’ingegneria del software e l’intelligenza artificiale.
Qualche giorno fa ho letto un articolo di Vivek Trivedy, product lead di LangChain, intitolato “The Anatomy of an Agent Harness.” È un pezzo tecnico, scritto per chi costruisce agenti AI in produzione, ma la questione che solleva è più generale: cosa serve, oltre al modello, per fare qualcosa di utile con un LLM?
L’argomentazione di Trivedy ha una struttura precisa e mi ha convinto a scrivere questo post.
L’equazione
Il punto di partenza è un’equazione semplice: Agent = Model + Harness. Il modello è la componente probabilistica — il LLM che genera testo. L’harness è tutto il resto: l’infrastruttura che avvolge il modello e lo rende capace di svolgere un’attività utile in un contesto reale. Trivedy elenca i componenti dell’harness in modo sistematico: system prompt, tool e MCP (Model Context Protocol, connettori verso servizi esterni), logica di orchestrazione, gestione della memoria, filesystem, sandbox di esecuzione, meccanismi di verifica, hook e middleware.
Ogni elemento di questa lista ha un corrispondente tra i concetti dell’ingegneria del software classica.
I system prompt sono una forma di specifica del comportamento: definiscono il contratto d’uso del modello in un contesto dato, con una struttura che richiama le precondizioni e i requisiti di interfaccia. Gli strumenti e gli MCP sono interfacce verso servizi esterni — la stessa architettura a componenti e connettori che SE studia da decenni. La logica di orchestrazione rimanda alla gestione del flusso e dello stato delle operazioni: workflow management e process modeling. La memoria è la gestione del contesto tra le sessioni — persistent state management. E chi prova a farlo in modo serio scopre rapidamente che un file JSON o Markdown non basta: servono database relazionali, indici, query efficienti, garanzie di coerenza e di resilienza. Le tecnologie sviluppate in decenni di ingegneria dei dati per gestire grandi quantità di informazioni in modo affidabile tornano a essere esattamente ciò di cui si ha bisogno. I meccanismi di verifica sono il test e la validazione, applicati a un componente con output non deterministico. Hook e middleware sono i pattern classici dell’architettura a livelli.
L’ingegneria del software non scomparve dal discorso sull’AI perché il problema di costruire software affidabile si fosse dissolto. Scomparve perché i sistemi AI di prima generazione erano abbastanza semplici da non richiedere tutta questa infrastruttura. Con i LLM in produzione, l’infrastruttura è tornata. E con essa, la disciplina.
Considerazioni analoghe provengono da voci diverse del panorama tecnico. Birgitta Böckeler, Distinguished Engineer presso Thoughtworks, ha pubblicato su martinfowler.com un articolo intitolato “Harness engineering for coding agent users” che usa la stessa equazione e inquadra l’harness engineering come una disciplina emergente. Anthropic, nel suo documento “Building Effective Agents,” descrive gli stessi componenti infrastrutturali come prerequisiti per qualsiasi agente che funzioni in produzione.
Cosa non è cambiato
Nel 2023, quando i grandi modelli linguistici di nuova generazione sono diventati accessibili su larga scala, si è sottovalutato sistematicamente l'impatto sulla complessità dell'architettura. La tesi prevalente era che il modello — capendo il linguaggio naturale — avrebbe assorbito la complessità sistemica: non devi più progettare l'architettura, gestire lo stato né integrare i componenti. Basta descrivere l'obiettivo.
Due anni dopo, chiunque abbia provato a costruire un agente in produzione sa com’è andata. Per task semplici e isolati, la tesi regge. Per qualsiasi cosa più articolata — flussi multi-step, integrazione con sistemi esterni, coerenza tra le sessioni, gestione degli errori — la complessità sistemica riemerge. E quando ritorna, porta con sé le stesse domande che l’ingegneria del software ha sempre affrontato: come progetti il sistema, come gestisci lo stato, come verifichi che funzioni, come lo mantieni nel tempo.
La complessità si è spostata: dai moduli ai prompt, dalle interfacce ai tool, dai test unitari agli evaluation set. Il problema rimane concettualmente e sostanzialmente lo stesso — costruire sistemi che si comportano come previsto in condizioni che non avevi previsto — e richiede la stessa disciplina.
Le domande che sono nuove
Questo non significa che l’AI non ponga nuovi problemi. Ne pone due che l’ingegneria del software classica non ha ancora risolto in modo soddisfacente.
La prima riguarda la specifica. Come si specifica una componente il cui comportamento è probabilistico? Le triple di Hoare — {precondizione} operazione {postcondizione} — descrivono contratti deterministici: dato questo input in queste condizioni, otterrai questo output. Un LLM produce distribuzioni di output, non valori singoli. Puoi specificare che il sistema “di solito risponde bene” o che “supera l’80% dei casi di test”, ma la struttura formale sottostante è diversa. Esistono lavori sulla logica probabilistica di Hoare e sui contratti stocastici, ma il problema rimane aperto sul piano operativo: come si scrive un contratto per un componente non deterministico che sia utile a chi lo integra?
La seconda riguarda il test. Come si testa un componente il cui spazio di input è illimitato? I test tradizionali ragionano per casi: l’input A produce l’output B. Con un LLM, lo spazio degli input è infinito e l’output varia. Gli evaluation harness che si usano oggi — set di prompt campionati, giudici LLM, metriche aggregate — sono strumenti empirici più che metodologie formali. Funzionano, ma non offrono le garanzie che un test unitario classico offre nel proprio ambito. Questa è una lacuna metodologica reale, non una limitazione pratica passeggera.
Va detto che problemi analoghi sono stati affrontati in altri domini — sistemi di controllo stocastici, simulazioni — ma senza produrre soluzioni trasferibili alla pratica ingegneristica ordinaria. La novità non è nel problema in sé, ma nella sua scala e nella sua pervasività.
Il cerchio che si chiude
Torno all’articolo di Trivedy. Quello che ha scritto è, in effetti, lo schema di un manuale d’ingegneria per questo tipo di sistemi. Ogni sezione dell’harness che descrive è una risposta a un problema che SE ha già nominato, qualificato e studiato: specifica, integrazione, stato, verifica, manutenzione. Le risposte cambiano perché il componente centrale — il modello — è diverso da qualsiasi componente che SE abbia mai gestito. Ma le domande sono le stesse.
Leggendolo, mi è tornata in mente una conversazione del 1996 con un collega. Stavamo discutendo di architetture software, e io sostenevo che stessimo rifacendo, a livello architetturale, le stesse considerazioni metodologiche che David Parnas aveva formulato sulla modularizzazione negli anni Settanta. “Stiamo girando in tondo e pestando l’acqua nel mortaio”, dissi.
Il collega mi rispose: “Tu vedi le cose in due dimensioni, e in due dimensioni sembra un cerchio. Ma c’è una terza dimensione, ortogonale: la complessità. Essa sta aumentando. Se vedi la cosa in tre dimensioni, il cerchio diventa una spirale che sale.”
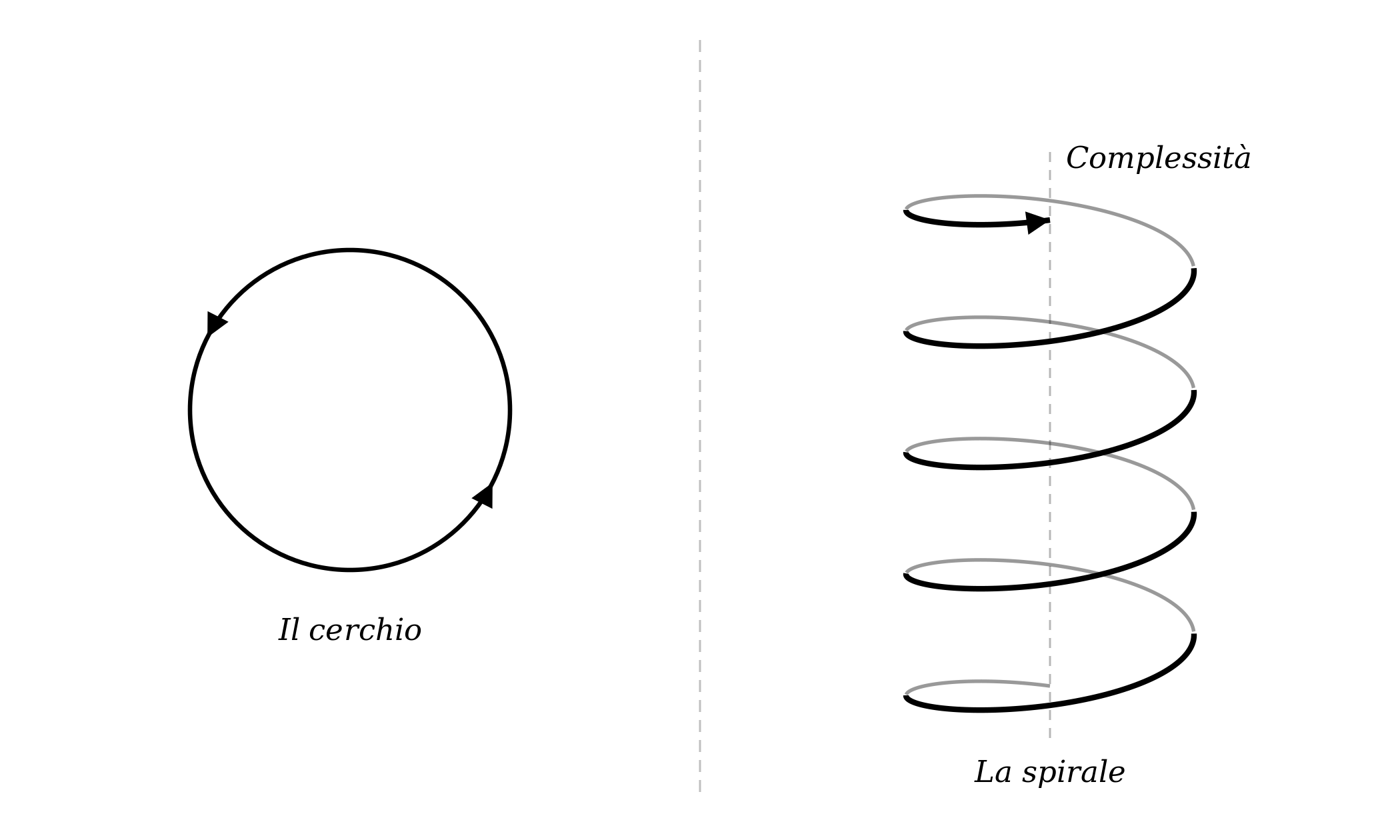
Aveva ragione allora e vale ancora oggi.
L'harness che Trivedy descrive è un giro della spirale a un livello di complessità più elevato, non una ripetizione di ciò che SE ha già fatto: componenti probabilistici, spazi di input illimitati, comportamenti che non puoi enumerare in anticipo. Le stesse domande di trent’anni fa — come specifichi, come testi, come mantieni — tornano in una forma che richiede risposte nuove.
Per chi viene da questa disciplina, come me — ho iniziato a metà degli anni Ottanta, in un periodo in cui "software crisis" non era una metafora ma una descrizione accurata della situazione — questi problemi sono riconoscibili: emergono ogni volta che si costruisce qualcosa che deve funzionare nel tempo, in condizioni reali, per utenti con esigenze che non avevi previsto.
Quello era il problema dell’ingegneria del software quando ho iniziato. Lo è ancora, solo più in alto sulla spirale.
Fonti: Vivek Trivedy, “The Anatomy of an Agent Harness,” LangChain blog
Birgitta Böckeler, “Harness engineering for coding agent users,” martinfowler.com
Anthropic, “Building Effective Agents,” anthropic.com
Questo post è stato scritto con l'assistenza di Claude. Le idee, le posizioni e il ragionamento sono miei.
© 2026 Alfonso Fuggetta & Sonia Montegiove. Salvo diversa indicazione, tutti i contenuti di questa pubblicazione sono protetti da copyright e rilasciati con licenza CC BY-NC-ND 4.0: https://creativecommons.org/licenses/by-nc-nd/4.0/deed.it
Questa fa io paio con quanto scoperto dal paper che ho commentato qui:
https://lucianoballerano.substack.com/p/quanto-codice-ia-ce-dentro-claude?r=3zs94o